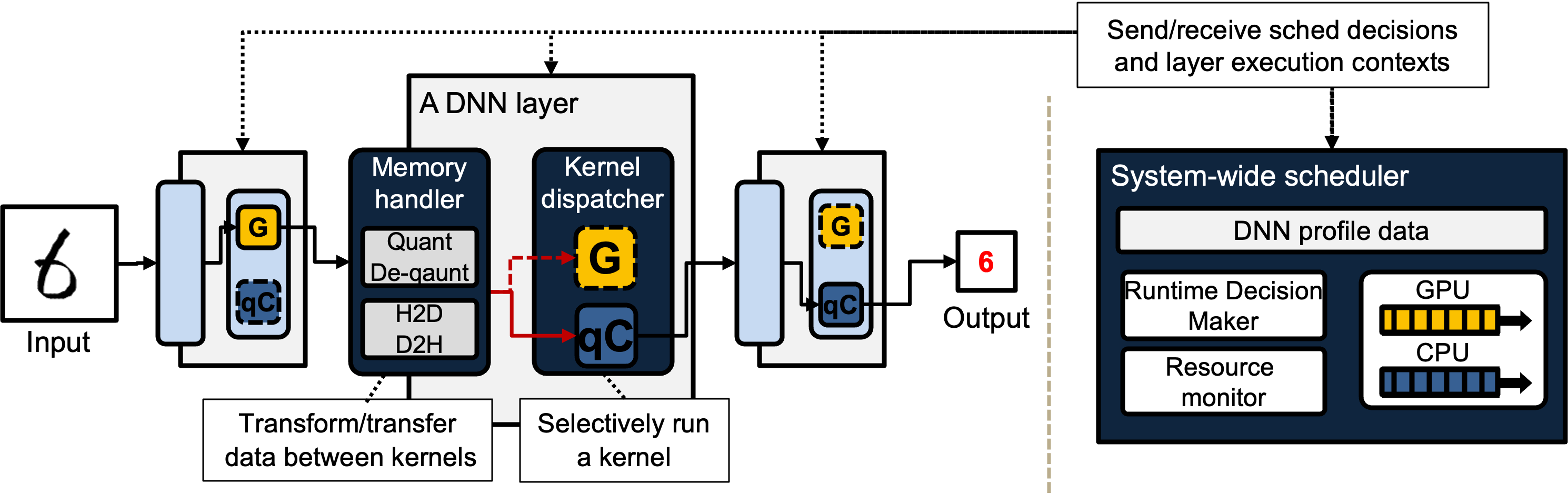
Deep neural networks (DNNs) have shown remarkable success in various machine-learning (ML) tasks useful for many safety-critical, real-time embedded systems. The foremost design goal for enabling DNN execution on real-time embedded systems is to provide worst-case timing guarantees with limited computing resources. Yet, the state-of-the-art ML frameworks hardly leverage heterogeneous computing resources (i.e., CPU, GPU) to improve the schedulability of real-time DNN tasks due to several factors, which include a coarse-grained resource allocation model (one-resource-per-task), the asymmetric nature of DNN execution on CPU and GPU, and lack of schedulability-aware CPU/GPU allocation scheme. This paper presents, to the best of our knowledge, the first study of addressing the above three major barriers and examining their cooperative effect on schedulability improvement. In this paper, we propose LaLaRAND, a real-time layer-level DNN scheduling framework, that enables flexible CPU/GPU scheduling of individual DNN layers by tightly coupling CPU-friendly quantization with fine-grained CPU/GPU allocation schemes (one-resource-per-layer) while mitigating accuracy loss without compromising timing guarantees. We have implemented and evaluated LaLaRAND on top of the state-of-the-art ML framework to demonstrate its effectiveness in making more DNN task sets schedulable by 56% and 80% over an existing approach and a baseline (vanilla PyTorch), respectively, with only up to -0.4% of performance (inference accuracy) difference.