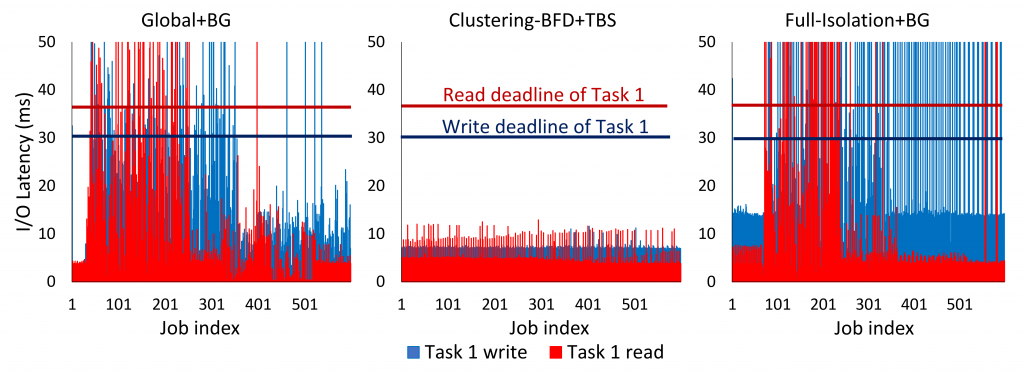
We illustrate a measurement-based case study to motivate our approach. We use an emulated SSD drive. Via this case study, we examine the effect of different levels of flash chip isolation on the worst-case latency of an real-time I/O request. We first compare two simple approaches for chip isolation over m chips: shared (i.e. no isolation) and fully-isolated resources. Under the shared approach, all I/O requests are allowed to read/write data across m chips as existing SSDs do. Under the full-isolation approach, each I/O request is statically assigned to a single chip and is allowed to read/write data on that chip only. Figure (a) and (c) show the worst-case latency of an real-time I/O request under the shared and fully-isolated approaches, respectively. Under the shared approach, GC is triggered less frequently than the fully-isolated approach because free space available in all the chips can be utilized by all the tasks. However, each task suffers from high GC interference by other tasks, which results in the violation of its timing constraints. Under the fully-isolated approach, there is no GC interference of other I/O requests. However, it suffers from high GC overheads to reclaim free pages since free pages in other chips cannot be utilized. This results in violating its timing constraints. To overcome disadvantages of both approaches, we consider an- other approach, called cluster-based isolation, using a notion of (chip) cluster. Fig. 1b shows the worst-case latency of an real-time I/O request under the cluster-based approach. By trading-off between resource contention by sharing chips and garbage collection overhead by isolating chips, we can achieve a lower worst-case latency than both the shared and fully-isolated approaches, satisfying the timing constraint.